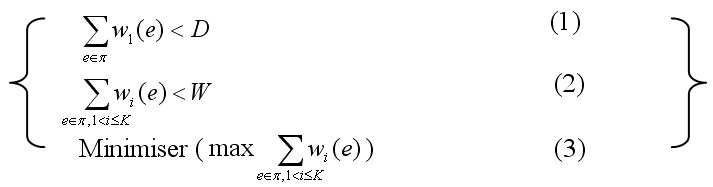
Mes autres Thématiques de Recherche
Mes autres thématiques de recherche incluent :
Selon le contexte et le domaine étudié, mes travaux de recherche pourraient être groupés dans trois classes : routage multi-contraint avec incertitudes dans les réseaux inter-domaines, routage dans les réseaux optiques, protection et optimisation des ressources.
Avec la généralisation et la facilité d’accès à l’Internet, nous assistons aujourd’hui à une augmentation significative du nombre d’applications déployées dans les réseaux. Certaines de ces applications, comme la VoiP, la TV sur internet et la visio-conférence nécessitent la vérification de plusieurs paramètres de qualité de service, comme le délai, le taux d’erreur, le coût financier, etc. Dans ce cadre, déterminer un routage efficace permettant de satisfaire (ou d’optimiser) un ensemble de contraintes liées à la qualité de service est primordial pour assurer le bon fonctionnement de ces applications.
Depuis octobre 2009, je m'intéresse au problème NP-difficile de recherche de chemins, dans les réseaux inter-domaines, optimisant ou vérifiant un ensemble de contraintes liées à K (K>1) métriques additives. Notons que la difficulté de notre problème n’est pas liée au routage multi-contraint uniquement (qui est lui-même NP-difficle) mais aussi à l’utilisation de réseaux inter-domaines où l’information sur la topologie et les poids des métriques dans chaque domaine est locale et n’est pas partagée avec les autres domaines. Ainsi, même si l’on dispose de tous les segments de chemins vérifiant les contraintes dans chaque domaine, la détermination d’un chemin de bout en bout vérifiant les mêmes contraintes reste NP-difficile.
Pour des raisons liées au passage à l’échelle et à la confidentialité, les domaines ne pourraient pas en général annoncer tous les segments de chemins reliant les nœuds d’entrée aux nœuds de sortie. Un sous-ensemble de ces segments, maximisant la probabilité de détermination d’un chemin de bout en bout qui vérifie les contraintes, doit donc être sélectionné. Dans ce cadre, mon travail (pour les six prochains mois) consiste à déterminer des approches probabilistes (routage avec incertitudes) permettant de sélectionner les segments de chemins dans les domaines et de les combiner pour la résolution du problème de routage multi-contraint dans les réseaux inter-domaines.
Réseaux inter-domaines, QoS, pré-calcul de chemins, algorithmes d’approximation à temps polynomial, complexité, discrétisation, mise à l’échelle, incertitudes.
Algorithme d’approximation du poids du lien de congestion (AAPLC)
Pour réduire le délai d’établissement des connexions, chaque domaine peut pré-calculer un ensemble de segments de chemin reliant ses nœuds d’entrée aux nœuds de sortie et vérifiant divers ensembles de contraintes. Afin d’accélérer les calculs, on est souvent amené à restreindre l’intervalle de recherche des solutions à [Binf, Bsup] où Binf et Bsup correspondent respectivement aux borne inférieure et borne supérieure aux solutions optimales. Un des meilleurs couples (Binf, Bsup) qui réduit l’intervalle de recherche des solutions est donné par le lien de congestion (bottlneck link). Par exemple, pour déterminer un chemin optimal π qui vérifie les équations (1) et (3), le lien de congestion eb permet de réduire l’intervalle de recherche des solutions (du système d’équations (A)) à l’intervalle [Binf (el) = max ∑1<i≤K wi (eb), Bsup (el) = Binf (el) * H] oùBsup (el) / Binf (el)= H. Nous notons que :
H est la longueur maximale d’un chemin,
wi (e) est le poids de la ième métrique,
Pour des considérations de confidentialité (les topologies et poids des liens ne sont pas annoncés aux autres domaines) et pour réduire les calculs, nous avons proposé un algorithme d’approximation (AAPLC) pour le calcul du poids maximal du lien d’étranglement dans les réseaux inter-domaines. En agrégeant et approximant les poids des liens par des puissance de la constante Cste (Cste > 1), notre algorithme est capable de déterminer deux réels a et b de telle sorte que a ≤ Bsup (el) ≤ b = a * Cste. Cela permet de déduire deux bornes Binf et Bsup aux solutions optimales du système (A) avec Binf / Bsup ≤ Cste * H.
Ce dernier résultat est très utile surtout lors de l’utilisation des algorithmes d’approximation à temps complètement polynomial (Fully polynomial time approximations schemes ou FPTAS) où la complexité de calcul reste inchangée avec la substitution de (Binf, Bsup) à (Bsup (el), Binf (el)).
Algorithme d’approximation basée sur une échelle hybride (AAEH) pour améliorer le routage multi-contraint
Pour permettre le pré-calcul de chemins vérifiant et/ou optimisant divers paramètres de la QoS, nous avons proposé l’algorithme AAEH. Pour n’importe quelle valeur de la contrainte D du système (A), notre algorithme est capable de déterminer un chemin ε-proche de l’optimal.
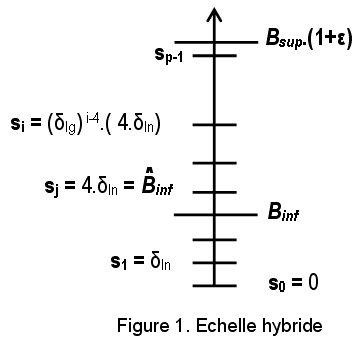
Notre algorithme AAEH combine trois concepts : (1) la discrétisation, (2) la mise à l’échelle et (3) le calcul des chemins. Le premier concept permet de réduire la complexité en discrétisant l’intervalle réel des poids des chemins [0, Bsup.(1+ε)] par le choix de r échantillons (s0, s1, .., sr-1). A chaque étape de la construction d’un chemin (chaque fois qu’un lien est ajouté à un chemin), le poids de la ième métrique du chemin est approximé par l’échantillon qui lui est supérieur et qui est le plus proche. Nous notons que les valeurs des différents échantillons sont déterminées par l’algorithme suivant :

Le second concept n’est pas nécessaire pour le bon fonctionnement de l’algorithme AAEH. Il permet uniquement d’éviter les divisions à chaque étape d’approximation d’un poids par l’échantillon qui lui correspond. Le troisième concept consiste à appliquer un algorithme exact de calcul des chemins multi-contraints en substituant aux poids réels des chemins les échantillons qui leur correspondent.
Je note que l’exactitude de l’algorithme AAEH est prouvée formellement dans ce papier. Parmi les résultats importants obtenus dans ce cadre, je cite :
Concernant l’algorithme AAPLC, le concept de mise à l’échelle et le calcul de chemins multi-contraints dans les réseaux inter-domaines, ils seront décrits en détails dans un autre papier.
Pour faire face aux demandes croissantes des utilisateurs en débit, la technologie de l’optique est non seulement choisie comme solution dans le cœur du réseau mais aussi dans de nombreux réseaux d’accès (numericable, free, etc.). Pour utiliser au mieux cette technologie, le multiplexage en longueur d’onde (WDM) est souvent adopté. A cause des contraintes liées à l’optique et à la continuité des longueurs d’onde, l’allocation des ressources (particulièrement les longueurs d’onde) et le routage dans les réseaux optiques est souvent difficile à réaliser.
Pendant l’année où j’ai été ATER, je me suis penché sur ces réseaux afin de rechercher de nouveaux algorithmes de routage (point à multipoint et multipoint à point) permettant d’utiliser au mieux les ressources (réduire le stress et les coûts) tout en améliorant la qualité de service (minimiser l’énergie pour éviter la distorsion du signal).
Réseaux optiques, calcul de chemins, communications point à multipoint et multipoint à point, routage, longueur d’onde.
Routage multipoint à point minimisant le stress (k-Bound Edge Disjoint Path Routing ou EDPR)
Afin de minimiser le stress tout en assurant un routage au pire k fois plus loin de l’optimum (par rapport à une métrique additive correspondant au coût par exemple), nous avons proposé l’algorithme EDPR. Ce dernier combine différents arbres constitués de chemins disjoints au pire k fois plus loin de l’optimum pour réduire le nombre de longueurs d’onde allouées. L’algorithme EDPR est décrit en détails dans cet article.
Avec l’explosion du nombre d’applications temps réel déployées dans les réseaux (comme la voix sur IP, la TV, les jeux en réseau, etc.), la récupération rapide des pannes est de plus en plus désirée pour assurer la continuité des services de communication. Différentes techniques de résistance aux pannes ont été développées pour éviter et/ou réduire le temps de coupure des communications affectées par une panne. Ces techniques ont pour rôle de déterminer des chemins de secours capables de recevoir et de rerouter le trafic des communications affectées par une panne. Elles peuvent être classées en deux catégories : restauration (ou protection réactive) et protection (ou protection proactive).
Avec la restauration, aucun calcul de chemin de secours n’est accompli avant l’occurrence d’une panne. Le processus de récupération, déclenché après la survenue d’une panne, consiste à déterminer et à configurer de nouveaux chemins contournant les composants défaillants et capables de router le trafic des communications affectées par la panne. En plus de sa capacité à résister aux changements de la topologie du réseau, la restauration a l’avantage de décroître les coûts de maintenance et de calcul. Cependant, elle n’assure aucunement la disponibilité des ressources (particulièrement la bande passante) après une panne et son délai de récupération est souvent élevé et inacceptable pour beaucoup de types d’applications réseaux (VoiP, TV, jeux en réseau, etc.).
Pour éviter les inconvénients précédents, la tendance actuelle est d’utiliser le second type de techniques de résistance aux pannes qui est la protection. Avec ce type de technique (la protection), le délai de récupération est significativement réduit car les chemins de secours sont pré-calculés et souvent préconfigurés avant l’occurrence des pannes. Concrètement, pour pallier une panne donnée, il suffira de basculer le trafic des communications affectées par la panne vers les chemins de secours qui les protègent.
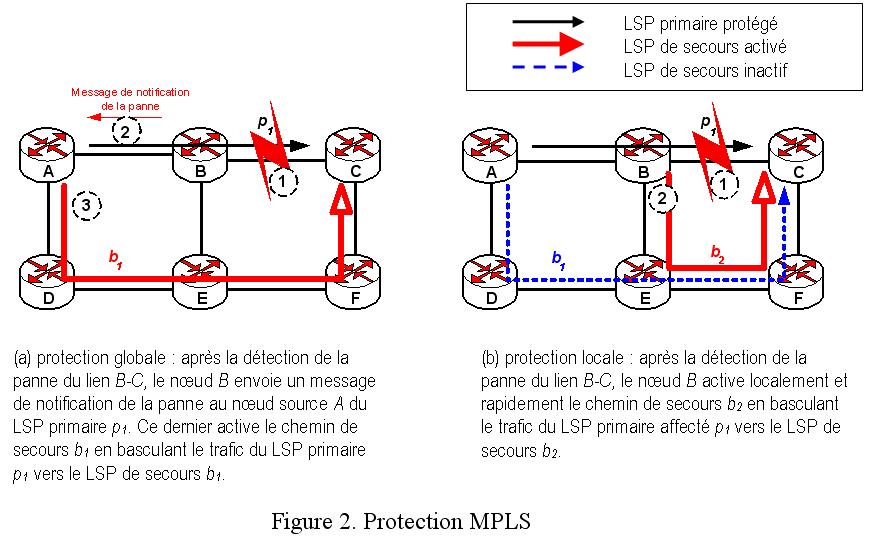
Selon la localisation du routeur responsable du basculement du trafic vers les chemins de secours, nous distinguons deux principales classes de protection : protection globale et protection locale (voir la figure 1). Avec la protection globale, ce sont les routeurs sources des communications affectées par la panne qui basculent le trafic des communications affectées vers leurs chemins de secours. Pour ce faire, un plan de contrôle notifiant la panne aux routeurs sources des communications affectées est nécessaire et est prévu. Concrètement, tout routeur détectant une panne construit un message de notification de la panne qu’il envoie à tous les routeurs sources des communications affectées. A cause du délai induit par la notification de la panne, la protection globale peut présenter des délais de récupération élevés (surtout si la panne est loin de la source) et indésirables pour certains types d’applications. Afin de minimiser le délai de récupération, le choix de la protection locale qui élimine le plan de contrôle notifiant la panne s’impose dans les réseaux en général et particulièrement dans les plus larges. Avec cette classe de protection, ce sont les routeurs détectant la panne (ou les routeurs très proches de la panne) qui réagissent à la défaillance en basculant localement le trafic des communications affectées vers les chemins de secours permettant la récupération. En plus des avantages de l’élimination des messages de notification de la panne et de la réduction du délai de récupération, la protection locale évite la perte d’un grand nombre de paquets après une panne.
Avec l’arrivée de MPLS (MultiProtocol Label Switching) dans la dernière décennie, la protection locale a été améliorée et rendue plus efficace. Grâce à sa grande flexibilité pour le choix des routes et à sa capacité de réserver explicitement les ressources (plus particulièrement la bande passante) et à préconfigurer des chemins de secours locaux, MPLS permet (1) de réduire sensiblement les délais de récupération (jusqu’à 50 millisecondes), (2) d’assurer la disponibilité des ressources après une panne et (3) d’optimiser l’utilisation des ressources.
Selon le nombre de pannes simultanées que doivent traiter avec succès les techniques de protection employées, la quantité de bande passante (ressource) allouée aux chemins de secours peut être plus au moins élevée. En effet, le nombre de pannes simultanées détermine tous les scénarios de pannes possibles, qui à leur tour, contrôlent le nombre et les structures des chemins de secours fournissant la protection. A cause de la rareté des pannes multiples et à la difficulté de protéger contre ce type de panne, beaucoup de travaux dans la littérature ne considèrent que les pannes simples. Avec ce dernier type de panne, la quantité de bande passante allouée aux chemins de secours est sensiblement diminuée et peut être optimisée grâce au partage de bande passante. Pratiquement, comme il ne peut y avoir qu’une seule panne à la fois dans un réseau, les ensembles de chemins de secours qui protègent contre des pannes différentes ne peuvent être actifs en même temps : ils peuvent donc partager leur allocation de bande passante sur les liens en commun.
En conséquence, pour minimiser le taux de rejet des requêtes de protection, le partage de bande passante doit être pris en compte lors du calcul des chemins de secours. Dans les travaux de recherche que j’ai effectués pendant ma thèse, je me suis intéressé au calcul en ligne et distribué des chemins de secours vérifiant les contraintes de la bande passante tout en la partageant dans une plate-forme de type MPLS. Trois types de risques de panne ont été pris en compte dans mes recherches : le lien, le nœud et le SRLG (Shared Risk Link Group). Malgré l’importance de ce dernier type de risque de panne (les SRLG peuvent être utilisés pour traiter les cas de plusieurs pannes simultanées, par exemple) et sa présence dans un grand nombre de réseaux d’aujourd’hui, rares sont les travaux qui le prennent en considération.
Pour des raisons liées aux performances, j’ai choisi le mode de calcul en ligne qui accélère les calculs et évite les reconfigurations des chemins déjà établis. J’ai aussi opté pour un modèle de calcul distribué afin d’augmenter la réactivité des serveurs de calcul et pour éviter un allongement sensible des délais de calcul après une panne. Enfin, pour des raisons de facilité de déploiement, j’ai tenu compte de deux contraintes :
Dans ma thèse, j’ai étudié le problème de placement des chemins de secours dans le cadre de l’unicast et du multicast. Dans la partie unicast, mes recherches ont été orientées vers la détermination de solutions distribuées agrégeant et diminuant l’information de contrôle annoncée dans le réseau pour le calcul des chemins de secours. Pour la partie multicast, mes recherches ont consisté à adapter les solutions unicast pour permettre de protéger des communications point à multipoint J’ai aussi comparé différentes stratégies de partage de la bande passante et j’ai étudié leur impact sur les mécanismes de placement des chemins de secours point à multipoint
Protection locale et en ligne des communications contre les pannes, optimisation de la bande passante par un partage efficace des ressources entre les communications, routage et graphes, SRLG (Shared Risk Link Group), calculs distribués, unicast et multicast.
Durant ma thèse, nous avons élaboré et proposé différents mécanismes permettant le calcul distribué des chemins de secours locaux (point à point et point à multipoint) dans une infrastructure de communication de type MPLS. Nos propositions ont pour avantage d’être faciles à déployer (quelques légères extensions des protocoles de routage et/ou de signalisation sont suffisantes) et elles réduisent le volume d’informations transmises dans le réseau pour permettre le placement des chemins de secours. Nous avons aussi proposé une méthode de protection des communications multicast et avons étudié l’impact du choix de différentes stratégies de partage de la bande passante sur les performances des mécanismes de placement des chemins de secours.
Nos principales contributions, ayant fait l’objet pour la plupart de publications dans des conférences et journaux internationaux, sont résumées ci après :
Algorithme TDRA
TDRA permet de maximiser le partage de la bande passante sur les liens en réduisant la quantité d’informations transmises dans le réseau. Pour ce faire, TDRA effectue une distribution ciblée et optimisée (utilisation d’arbres de Kou-Markowsky-Berman pour la distribution de l’information requise aux calculs des chemins) de l’information requise pour le calcul distribué des chemins de secours. L’implantation de cet algorithme ne requiert que de légères extensions des protocoles de signalisation (et des extensions minimes des protocoles de routage).
Heuristique DBSH
DBSH permet le placement des chemins de secours en ne diffusant qu’une information partielle et agrégée dans le réseau. Avec cette heuristique, le calcul de tous les chemins de secours protégeant contre la panne d’un nœud donné (resp. d’un lien unidirectionnel donné) sont effectués sur le nœud lui même (resp. sur le nœud sortant du lien). Cette heuristique réduit considérablement la taille de l’information diffusée dans le réseau et elle est facile à déployer puisqu’elle ne requiert que de légères extensions aux protocoles de routage et aux protocoles de signalisation.
Heuristique PLRH
PLRH permet le placement des chemins de secours en ne diffusant qu’une information partielle et agrégée dans le réseau. Avec cette heuristique, tous les calculs des chemins de secours sont effectués par les routeurs de tête de ces chemins. Cette heuristique a pour avantages d’être symétrique (toutes les entités de calcul disposent de la même information) et facile à déployer (elle ne nécessite que de très légères extensions aux protocoles de routage).
Exploitation des structures des SRLG pour un placement efficace des chemins de secours
Pour améliorer le taux de protection et augmenter la disponibilité des ressources, nous avons proposé d’exploiter les structures des SRLG lors du calcul des chemins de secours. En constatant que certains chemins de secours actifs après une panne d’un SRLG ne peuvent recevoir du trafic, nous avons proposé de restreindre l’ensemble des risques protégés par un chemin de secours à ceux dont la panne induit la réception du trafic.
Protection multicast par forêt duale
Pour protéger les communications multicast, nous avons proposé d’utiliser une structure de secours formée d’une forêt reliant les nœuds feuilles de l’arbre multicast. Cette méthode de protection a l’avantage de réduire la taille de la structure de secours ; elle permet donc d’améliorer la disponibilité des ressources avant et après une panne.
Impact du choix de la stratégie de partage de la bande passante sur les performances des mécanismes de placement des chemins de secours
Nous avons étudié l’impact du choix de la stratégie de partage de la bande passante employée sur les performances des mécanismes de placement des chemins de secours. Deux stratégies de partage de la bande passante ont été comparées : (1) partage de la bande passante entre les chemins de secours uniquement et (2) partage de la bande passante entre les chemins primaires et de secours. Dans notre étude, nous avons employé un algorithme de calcul basé sur les plus courts chemins en termes d’une métrique statique (i.e. métrique fixe et indépendante du trafic). Avec un tel algorithme, nous avons prouvé analytiquement et montré par simulations que l’extension du partage des ressources au partage de la bande entre les chemins primaires et les chemins de secours ne permet qu’une légère réduction du taux de rejet des requêtes de placement des chemins de secours. En d’autres termes, nous avons démontré que le nombre de requêtes de placement de chemins de secours satisfaites est borné et dépend plus du partage de la bande passante entre les chemins de secours ; l’impact du partage de la bande passante entre les chemins primaires et les chemins de secours sur la réduction du taux de blocage des requêtes de placement de chemins de secours est limité et est borné.
Pour mes publications, cliquez ici.